Ahmed Shehata

Data Scientist
Technical Skills, Libraries and Software Tools
Python; C; Command Line; SQL; Seaborn; Exploratory Data Analysis; NumPy; Pandas; Matplotlib; Scikit-learn; SciPy; Power BI; Tableau; Canva, Microsoft Excel; Microsoft PowerPoint; Microsoft Office; Database Management; Data Preprocessing; Data Wrangling; Data Cleaning; Predictive Modelling; Generative AI; Deep Learning; Model Employment; Machine Learning; Hyperparameter tuning; Exploratory Data Analysis; Hypothesis A/B testing; Business Intelligence; Ensemble Techniques; Supervised Learning; Classification; Unsupervised Learning; Statistical Analysis; AdaBoost, Gradient Boosting, XGBoost; Dashboard Development; Decision Tree Algorithms; Linear Regression; K-means and Hierarchical Clustering
Education
-
Post Graduate Programme, Data Science and Business Analytics Texas McCombs School of Business (Aug 2023 - May 2024) -
Bachelor of Science, Medical Science Oxford Brookes University (Sep 2020 - May 2023)
Work Experience
Data Analyst and Marketing Intern @ FHS Law Consultants (Sept 2022)
- Re-engineered marketing strategies, leveraging data analysis to optimize operations and achieve a 10% decrease in resource allocation for underperforming areas, enhancing overall efficiency and cost-effectiveness of marketing efforts.
- Utilised data-driven methodologies to construct dashboards, generate reports, and design data visualisation, uncovering insights that led to a 15% increase in client conversion rates and a 20% improvement in marketing campaign ROI.
- Executed digital marketing campaigns, resulting in a 25% increase in website traffic, a 30% rise in social media engagement, and a 20% improvement in email marketing click-through rates, driving measurable improvements in online presence and audience engagement.
Healthcare Data Analyst Intern @ Al Zaabi Healthcare (ADAM & EVE) (Aug 2022)
- Implemented Pandas, NumPy, and Excel to enhance data quality by 20% for senior management through thorough data cleaning and preprocessing, optimizing data integrity and analysis efficiency.
- Utilized Tableau to visualize healthcare service data, facilitating hospital management teams in identifying improvement areas, leading to a significant 40% reduction in waiting time from 10 to 6 minutes, enhancing operational efficiency and patient satisfaction.
Property Analyst Intern @ AMIGO Properties (Real Estate) (Jul 2022)
- Leveraged advanced Excel functions, including data cleaning, pivot tables, index matching, and formatting for insightful property data analysis. Facilitated seamless data transfer to SQL databases.
- Executed a linear regression machine learning model to analyse property prices based on location and other features employing A/B hypothesis testing by implementing a revised property listing format for a subset of rental properties in the UAE, comparing engagement metrics to validate a 12% improvement and inform data-driven optimisations.
Leaderboard Coordinator and Tournament Oversight Manager @ Abu Dhabi Golf Club (Dec 2019 - Dec 2020)
- Orchestrated the seamless operation of leaderboards, developing a system streamlining data accuracy and real-time updates, resulting in improved viewer experience and event efficiency. Building a network connection between leaderboards to automatically update golfers’ scores, sending them directly to be manually inputted by colleagues, increasing real-time update efficacy by 33%.
Special Needs Cycling Instructor and Volunteer @ GMS Special Olympics (Sep 2018 - May 2019)
- Utilised data analysis and research insights to customise cycling programs for children with special, achieving an 80% completion rate of training with 75% of participants riding a cycle unassisted by the end of the internship. Collaborated with volunteers and professionals to implement data-driven approaches, integrating findings from research papers, and facilitating effective communication within the team to optimise program effectiveness and deliver personalised outcomes for each participant.
Event Management and Media Awareness Coordinator @ Emirates Red Crescent (Sep 2018 - May 2019)
- Analysed engagement metrics and demographic data to tailor communication strategies for charitable initiatives at Emirates Red Crescent, resulting in a 33% increase in online engagement and a 30% rise in event attendance. Utilised data insights to identify target audiences and optimise messaging, fostering stronger connections with stakeholders and enhancing community participation in philanthropic efforts, including a televised staff event on Abu Dhabi TV.
Health and Ergonomics Research Assistant @ Perfect Balance Rehabilitation Center (Sep 2018 - May 2019)
- Directed research and development efforts for a workplace wellness program, devising tailored stretches and preventivemethods. Leveraged data-driven approaches to analyze employee health data and strategise program implementation, resulting in a 20% decrease in reported pain levels and fostering a healthier work environment.
Projects
note: I am unable to provide specific statistics or data regarding the project publicly as they are copyrighted by PGP. For further information about the project, please feel free to contact me directly.
FoodHub Order Analysis: Python Foundations
Project Summary:
In the FoodHub Order Analysis project, conducted during the PGP Course, I analyzed data from a food aggregator company to derive actionable insights using Python. The project aimed to enhance customer experience by understanding the demand for various restaurants in New York, facilitated by the company’s online portal. Through extensive exploratory data analysis, including Variable Identification, Univariate analysis, and Bi-Variate analysis, I addressed key questions posed by the Data Science team to improve business strategies.
Key Highlights:
- Applied Exploratory Data Analysis techniques, including Variable Identification, Univariate analysis, and Bi-Variate analysis.
- Utilized Python for comprehensive data analysis.
- Collaborated with the Data Science team to decipher actionable insights.
- Employed statistical and analytical methods to extract valuable insights for strategic decision-making.
Skills List:
- Exploratory Data Analysis
- Variable Identification
- Univariate Analysis
- Bi-Variate Analysis
- Python
- Data Manipulation: numpy, pandas
- Data Visualization: matplotlib.pyplot, seaborn

E-news Express Project: A/B Testing
Project Summary:
Within the Business Statistics course, the E-news Express Project focused on evaluating the effectiveness of a new landing page for an online news portal, E-news Express. Utilizing statistical analysis, A/B testing, and visualization techniques, the project aimed to assess the page’s ability to attract new subscribers and examined the correlation between conversion rates and users’ preferred language.
Key Highlights:
- Applied statistical analysis methodologies such as Hypothesis Testing and A/B testing.
- Utilized Data Visualization techniques to present insights effectively.
- Examined critical metrics like conversion status and time spent on the page to draw conclusions.
- Investigated the influence of users’ preferred language on conversion rates.
- Engaged in Statistical Inference to derive meaningful insights and make informed decisions.
Skills List:
- Hypothesis Testing
- A/B Testing
- Data Visualization
- Statistical Inference
- Data Manipulation: numpy, pandas
- Data Visualization: matplotlib.pyplot, seaborn
- Statistical Libraries: scipy.stats

ReCell Project: Supervised Learning Foundations
Project Summary:
The ReCell Project, conducted during the Supervised Learning - Foundations course, focused on developing a dynamic pricing strategy for used and refurbished devices. Leveraging Python and advanced analytical techniques, including Linear Regression, the project aimed to identify key factors influencing device prices. By meticulously evaluating model assumptions and offering actionable insights, the project underscored the significance of data-driven strategies in optimizing pricing strategies.
Key Highlights:
- Applied Exploratory Data Analysis (EDA) to extract insights from the dataset.
- Implemented Linear Regression to develop a dynamic pricing model for used and refurbished devices.
- Rigorously evaluated and addressed assumptions underpinning Linear Regression to enhance model accuracy.
- Identified pivotal factors influencing device prices, fostering informed decision-making.
- Presented actionable business insights and recommendations grounded in the model’s findings.
Skills List:
- Exploratory Data Analysis
- Linear Regression
- Linear Regression Assumptions
- Business Insights and Recommendations
- Data Manipulation: numpy, pandas
- Data Visualization: matplotlib.pyplot, seaborn
- Statistical Libraries: scipy.stats
- Model Evaluation: train_test_split, statsmodels.api, mean_absolute_error, mean_squared_error

INN Hotel Analysis: Supervised Learning Classification
Project Summary:
In the INN Hotels project, conducted during the Supervised Learning - Classification course, the primary objective was to develop a predictive model capable of preemptively identifying bookings likely to be canceled. Leveraging supervised learning techniques such as Logistic Regression and Decision Tree algorithms, along with exploratory data analysis and data preprocessing, the project aimed to identify influential factors on booking cancellations and formulate profitable policies for cancellations and refunds.
Key Highlights:
- Conducted Exploratory Data Analysis (EDA) to understand dataset characteristics and patterns.
- Implemented Data Preprocessing techniques to clean and prepare the dataset for analysis.
- Utilized Logistic Regression and Decision Tree algorithms for classification tasks.
- Addressed Multicollinearity issues to ensure model robustness.
- Evaluated model performance using the Area Under the Curve - Receiver Operating Characteristic (AUC-ROC) curve.
- Employed pruning techniques to enhance decision tree model performance and interpretability.
Skills List:
- Exploratory Data Analysis
- Data Preprocessing
- Logistic Regression
- Multicollinearity
- AUC-ROC Curve
- Decision Tree
- Pruning
- Data Manipulation: pandas, numpy
- Data Visualization: matplotlib.pyplot, seaborn
- Model Evaluation: metrics, DecisionTreeClassifier
- Statistical Libraries: statsmodels.api
- Classification Techniques: Logistic Regression, Decision Tree
Actionable Insights and Recommendations:
Profitable policies for cancellations and refunds:
- Implement a deposit policy based on lead time and room price to incentivize guests to commit to their bookings.
- Consider collecting additional data directly from guests regarding cancellation reasons, origin (abroad/resident), and purpose of stay (business/vacation) to improve model predictions. Other recommendations:
- Develop a system to alert management when guests exhibit high-risk characteristics for cancellation, such as long lead times, special requests, and market segment.
- Continuously monitor and update policies based on insights gained from the predictive model to adapt to changing booking patterns and guest behaviors.

Easy Visa Project: Ensemble Techniques Bagging and Boosting
Project Summary:
In the EasyVisa project, conducted during the Ensemble Techniques course, the primary objective was to build a predictive model to streamline the visa approval process and recommend suitable applicant profiles for visa certification or denial. Leveraging ensemble techniques such as Bagging Classifiers (Bagging and Random Forest), Boosting Classifiers (AdaBoost, Gradient Boosting, XGBoost), and a Stacking Classifier, along with exploratory data analysis (EDA) and data preprocessing, the project aimed to identify influential factors on visa status and offer actionable insights for decision-making.
Key Highlights:
- Conducted Exploratory Data Analysis (EDA) to understand dataset characteristics and trends.
- Implemented Data Preprocessing techniques to clean and prepare the dataset for analysis.
- Utilized Customer Profiling methods to identify distinct applicant profiles.
- Employed Ensemble Techniques including Bagging Classifiers (Bagging and Random Forest), Boosting Classifiers (AdaBoost, Gradient Boosting, XGBoost), and a Stacking Classifier for classification tasks.
- Conducted Hyperparameter Tuning using GridSearchCV to optimize model parameters.
- Derived actionable Business Insights from the analysis to inform decision-making processes.
Skills List:
- Exploratory Data Analysis
- Data Preprocessing
- Customer Profiling
- Bagging Classifiers: Bagging, Random Forest
- Boosting Classifiers: AdaBoost, Gradient Boosting, XGBoost
- Stacking Classifier
- Hyperparameter Tuning using GridSearchCV
- Business Insights
- Data Manipulation: pandas, numpy
- Data Visualization: matplotlib.pyplot, seaborn
- Model Evaluation: metrics, GridSearchCV
- Classification Techniques: DecisionTreeClassifier, LogisticRegression
Actionable Insights and Recommendations:
Actionable Insights:
- Identified important features influencing visa status, such as previous job experience, payment method, and education level.
- Highlighted that applicants from Asia are more likely to face visa denials compared to other continents. Recommendations:
- Implement a checklist system to alert employees to investigate further when applicants exhibit high-risk characteristics.
- Develop sophisticated matching algorithms to match employment vacancies with appropriate candidates based on experience, skill sets, and company criteria.
- Utilize forecasting and predictive analytics to predict future trends in labor demand and streamline the visa approval process.

ReneWind Project: Model Tuning
Project Summary:
In the “ReneWind” project, our collaboration with a leading wind energy company focused on leveraging machine learning techniques to predict generator failures in wind turbines. By analyzing sensor data, our goal was to reduce maintenance costs and minimize downtime, ultimately enhancing operational efficiency and optimizing resource allocation.
Key Highlights:
- Exploratory Data Analysis (EDA): Conducted thorough EDA on generator failure data collected from wind turbines’ sensors to understand underlying patterns and relationships.
- Class Imbalance Handling: Implemented Up and Downsampling techniques to address class imbalance in the dataset, ensuring balanced representation of failure and non-failure cases.
- Regularization: Applied Regularization methods to prevent overfitting in classification models, thereby improving generalization performance on unseen data.
- Hyperparameter Tuning: Utilized Hyperparameter Tuning techniques such as GridSearchCV to optimize model performance and fine-tune model parameters for better predictive accuracy.
- Clustering Analysis: Compared K-means and Hierarchical Clustering techniques to identify patterns in turbine failure data, offering insights into potential groupings or clusters within the dataset.
- Business Recommendations: Derived actionable insights from clustering analysis results to inform strategic decision-making processes and optimize maintenance strategies.
Skills:
- Up and downsampling
- Regularization
- Hyperparameter tuning
- Exploratory Data Analysis (EDA)
- Data preprocessing
- Model evaluation and optimization
- Clustering techniques: K-means, Hierarchical Clustering
Actionable Insights and Recommendations:
- Feature Importance: Identified key features such as V18, V39, and V3 as significant predictors of generator failures, providing valuable insights into factors driving the target variable.
- Model Performance: Achieved optimal model performance using XGBoost with random search CV tuning, particularly excelling in recall and F1-score metrics, indicating the model’s effectiveness in identifying positive cases accurately.
- Interpretability Challenges: While the model demonstrates strong predictive performance, interpreting the significance of features may require domain-specific knowledge and context, highlighting the importance of collaborating with domain experts to decode the model’s output.
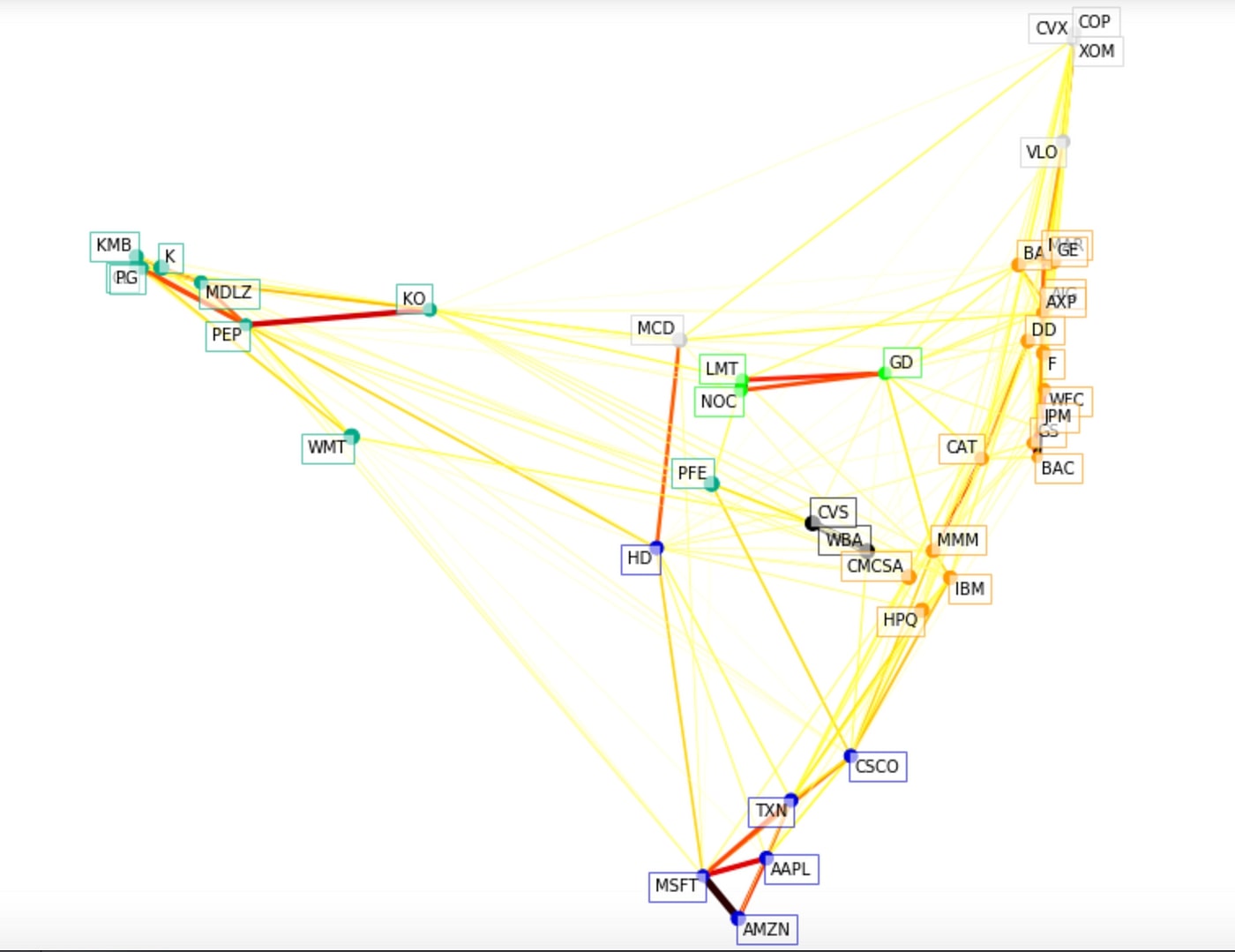
Trade&Ahead Project: Unsupervised Learning
Project Summary:
In the “Trade&Ahead” project, we collaborated with a financial consultancy firm to analyze stock data and group stocks based on their attributes. Our goal was to provide insights into the characteristics of each group, enabling personalized investment strategies for clients.
Key Highlights:
- Exploratory Data Analysis (EDA): Conducted thorough EDA on stock price and financial indicator data to understand underlying patterns and relationships.
- K-means Clustering: Utilized K-means clustering to group stocks based on similar characteristics, enabling the identification of clusters with distinct attributes.
- Hierarchical Clustering: Employed Hierarchical Clustering as an alternative technique to group stocks, comparing results with K-means clustering to assess similarities and differences.
- Cluster Profiling: Conducted cluster profiling to extract actionable insights and recommendations for each group of stocks, focusing on diversification opportunities, industry investments, risk management, operational efficiency enhancement, strategic pricing decisions, and liquidity management.
Skills:
- Exploratory Data Analysis (EDA)
- K-means Clustering
- Hierarchical Clustering
- Cluster Profiling
Recommendations:
- Diversification Opportunities: Explore partnerships with firms from other clusters for growth potential.
- Tech Industry Investment: Consider stocks dominated by tech giants for investment opportunities.
- Risk Management: Prioritize robust risk management strategies, especially in volatile sectors.
- Operational Efficiency: Optimize processes and cost-saving measures for enhanced efficiency.
- Strategic Pricing: Tailor pricing strategies based on market factors to optimize competitiveness.
- Liquidity Management: Ensure adequate cash reserves for financial resilience and stability.
Personal Projects
Credit Card Default
In our project, we aimed to develop a predictive model using machine learning classification techniques to assess the risk of default among loan applicants. By leveraging a range of data points including credit history and loan amount, we sought to enhance the accuracy of our model through both numeric and categorical attributes integration.
Key findings:
- We observed that features like credit history and checking balance wield significant influence in predicting defaults.
- Post-pruning decision trees emerged as the most effective method, boasting the highest recall rates.
Conclusion: Our examination underscored the critical importance of certain features, such as credit history and checking balance, in determining default risk. Furthermore, the utilization of post-pruning decision trees significantly enhanced our model’s recall rates, emphasizing their effectiveness in this context. These insights provide valuable guidance for future enhancements in credit risk assessment methodologies.
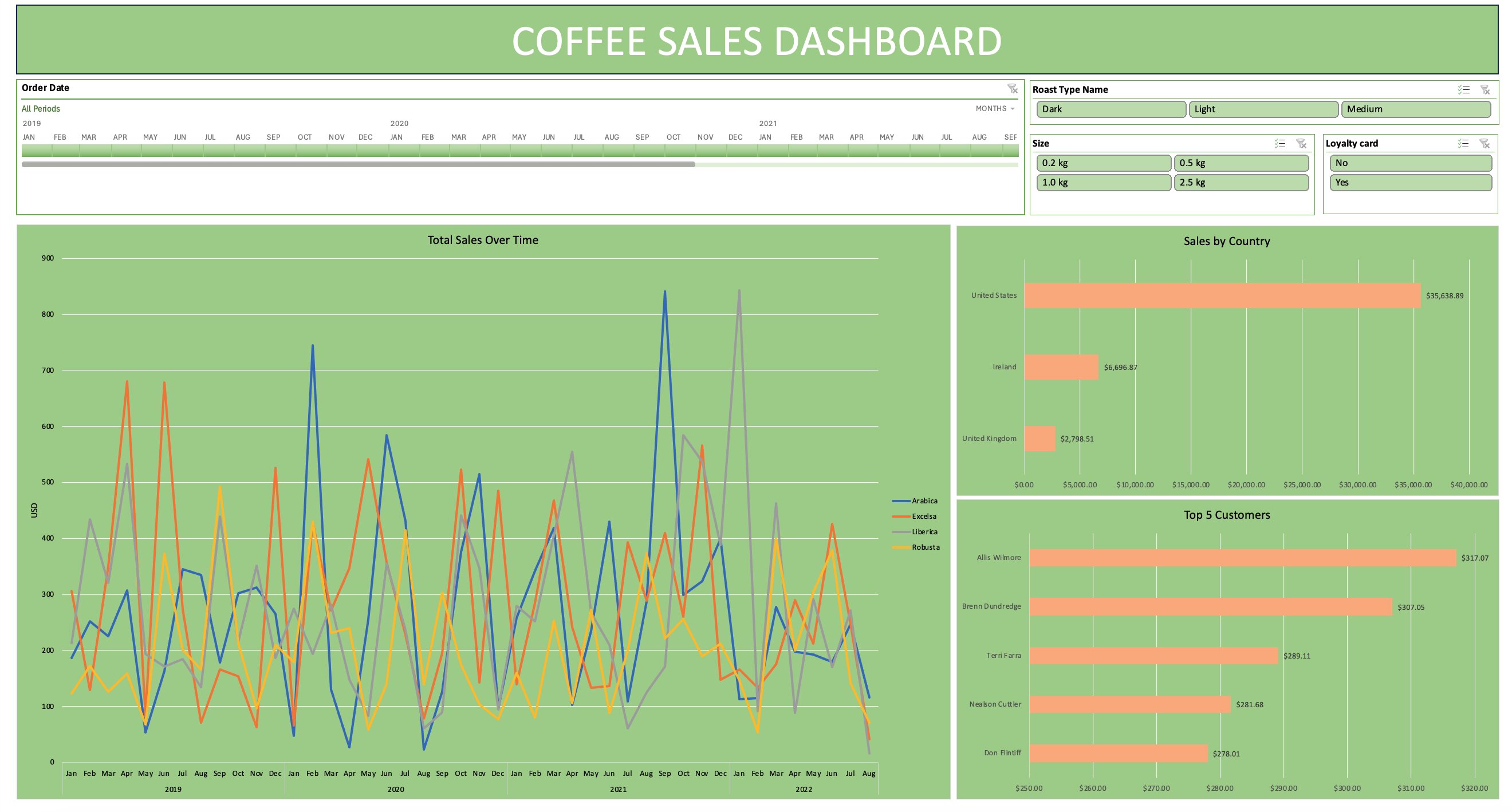
Coffee Sales Interactive Dashboard
Dashboard
Developed an interactive coffee sales dashboard featuring a timeline, slicers, and charts. Key skills utilized during the project walkthrough included XLOOKUP, INDEX MATCH, multiplication formulas, multiple IF functions, date and number formatting, checking for duplicates, converting ranges to tables, working with pivot tables and pivot charts, and formatting. Additionally, the dashboard was built, updated, and enhanced with pro tips for a comprehensive user experience. Note: You may have to downlad the file to use all features.

Analyzing Subscription Churn Rates: Leveraging Advanced SQL Techniques for Actionable Insights
SQL Project
In this project, we’re diving into subscription churn rates for Codeflix, a new streaming service. Our main goal is to figure out how many users are canceling their subscriptions over time. We’re also looking at two different groups of users to see if there are differences in how often they cancel. We’ll dig through the subscription data, following Codeflix’s rules like the minimum subscription length of 31 days. We’ll use some advanced SQL techniques like aggregates, unions, temporary tables, cross joins, case statements, and aliasing to do this. Our aim is to provide insights that help Codeflix keep users around and grow their business.

Personal Health Ring
This is my next upcoming project in this project I will download over 5 months of my personal activity and sleep metrics to assess my performance based on my “readiness level”, activity level and sleep. Other metrics will include body temperature, REM sleep, HRV, Steps, Equivalent Walking Distance and recovery index. This data will be used to assess how I could further improve my health and wellbeing as well as provide as overview of my physical performance over the last couple of months.